Automating reasoning about the future at Ought
Ought’s mission is to automate and scale open-ended reasoning. Since wrapping up factored evaluation experiments at the end of 2019, Ought has built Elicit to automate the open-ended reasoning involved in judgmental forecasting.
Today, Elicit helps forecasters build distributions, track beliefs over time, collaborate on forecasts, and get alerts when forecasts change. Over time, we hope Elicit will:
- Support and absorb more of a forecaster’s thought process
- Incrementally introduce automation into that process, and
- Continuously incorporate the forecaster’s feedback to ensure that Elicit’s automated reasoning is aligned with how each person wants to think.
This blog post introduces Elicit and our focus on judgmental forecasting. It also reifies the vision we’re running towards and potential ways to get there.
Ought Raises $3.8 Million
We’re excited to announce new donations totaling $3.8MM from the following donors:
- $2,593,333 from Open Philanthropy ($260,000 of this is made possible by a funding partnership with Effective Giving and Ben Delo)
- $900,000 from Paul Christiano
- $150,000 from Jaan Tallinn
- $100,000 from the Survival and Flourishing Fund
- $40,559 total from Nisan Stiennon, Jalex Stark, Girish Sastry, Peter McCluskey, Yuta Tamberg, Community Foundation for San Benito County Calhoun/Christiano Family Fund, Raphael Franke, and others (additional notes here and here)
We are grateful to be working with these philanthropic partners. While each of our donors has their own values and beliefs, we find that as a group they take a long-term and “hits-based” approach to giving. They consider where society will be decades from now, the opportunities and risks we will face along the way, and what they can do now to make the long-term future better. This in turn allows us to focus on what we think is right from a long-term perspective. Our donors recognize that Ought is an unusual research-product hybrid organization. They’re not afraid to engage with the knotty details of our research to collaborate on ways to maximize impact in the long term while measuring signs of progress in the short term.
Our partners’ support allows us to build towards a future world where individuals and organizations arrive at better answers to life's messy but important questions. There are many of these, like
- How do I decide whether to buy a house, save for retirement, or pay off my student loans?
- Should I pick a job that allows me to directly work on the problems I care about now, or one that will teach me skills to be more effective at solving that problem later?
- How should we set our hiring plan for the next 3-5 years given sales forecasts, competition, and other macroeconomic trends?
- How should we prioritize among this set of products or features we want to launch?
- I really like bread. Is it really that bad to be eating so much bread?
At first glance, each of these questions seems unique. But zooming out, answering them depends on a common core of reasoning. When people answer these questions today, they often
- Think about their values and preferences
- Gather evidence
- Compare and weigh the evidence
- Think through plans by comparing different paths or outcomes, making forecasts, or considering the likelihood of different scenarios
As AI and machine learning advance, we want to delegate parts of these processes to machines, especially the parts that machines do better, such as searching over a hundred thousand permutations of paths, gathering evidence from every single page on the Internet, and making forecasts based on gigabytes of data.
To successfully delegate some of this thinking to machines, we need to design systems that help us evaluate work that is too complex for us to evaluate directly. These systems also need to scale. They need to flexibly absorb diverse inputs and productively convert computation into better thinking and decision-making. AI has the potential to make answering these questions 100x or 1000x better.
But there's no guarantee that we’re headed towards this world. There are many pressures to build AI systems that optimize for quick, plentiful reward signals like retweets or video views - signals that look appealing instead of actually being good. It’s more challenging to think carefully about good reasoning and how it can help people figure out the answers they'd give if they had more time to think.
So we and our donors are taking the long-term view and building towards this world. Today, we're working on this problem in small-scale settings, mostly with human experts, but we're developing mechanisms designed to hold up even for very large-scale machine reasoning. If this is the kind of world you want to build too, get in touch.
Evaluating Arguments One Step at a Time
We’re studying factored cognition: under what conditions can a group of people accomplish complex cognitive tasks if each person only has minimal context?
In a recent experiment, we focused on dividing up the task of evaluating arguments. We created short, structured arguments for claims about movie reviews. We then tried to distinguish valid from invalid arguments by showing each participant only one step of the argument, not the review or the other steps.
In this experiment, we found that:
- Factored evaluation of arguments can distinguish some valid from invalid arguments by identifying implausible steps in arguments for false claims.
- However, experiment participants disagreed a lot about whether steps were valid or invalid. This method is therefore brittle in its current form, even for arguments which only have 1–5 steps.
- More diverse argument and evidence types (besides direct quotes from the text), larger trees, and different participant guidelines should improve results.
In this technical progress update, we describe these findings in depth.
Progress Update October 2019
This is an update on our progress towards our goals over the last ten months. If you can only read 650 characters of this update, like the judges in our experiments, here’s what you need to know:
- We switched from experiments that break down tasks (factored generation) to experiments that break down evaluating expert work (factored evaluation)
- 60+ participants have been working 150+ hours per week on our experiments
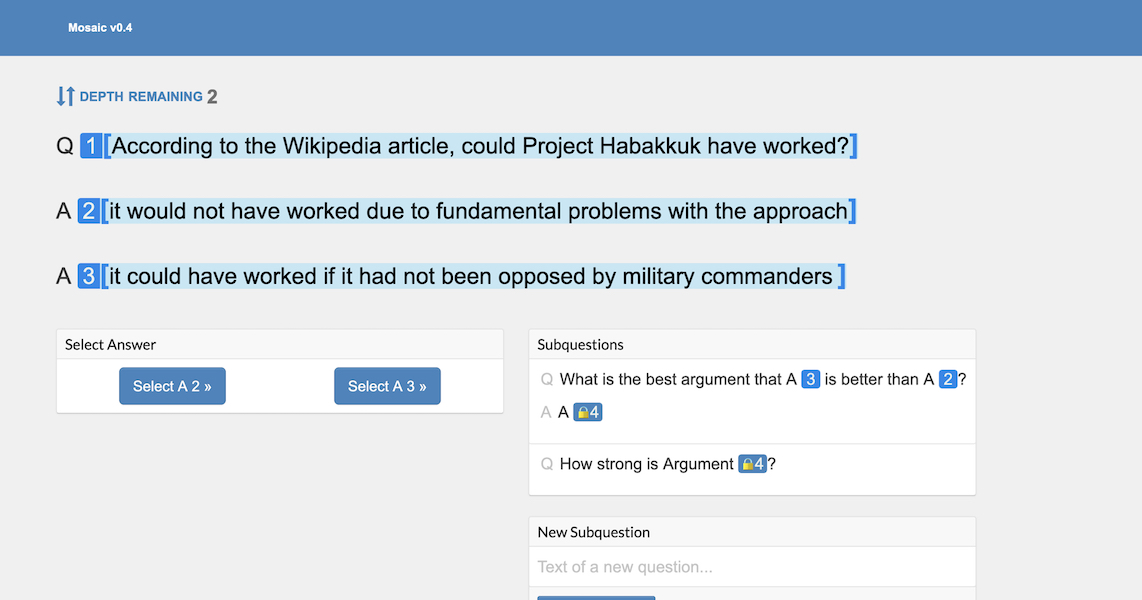
- We're building Mosaic2, an app that streamlines running varied question-answer experiments (factored evaluation, debate, etc.)
- We're exploring if language models can automate decompositions, getting 30% accuracy on the Complex Web Questions dataset
- William Saunders joined as ML engineer, Jungwon Byun as COO
- We’re hiring an engineering team lead and a business operations person. We’ll pay $5000 for a successful referral!
Talk transcript: Delegating open-ended cognitive work
We've published an edited transcript for a talk I gave at EA Global 2019. This talk gives an update on the core problem we're trying to solve at Ought and shows what our current experiments look like.
The summary:
In the long run, we want machine learning (ML) to help us resolve open-ended questions like “Should I get this medical procedure?” and “What are the risks in deploying this AI system?” Currently, we only know how to train ML if we have clear metrics for success, or if we can easily provide feedback on the desired outputs. This modified talk (originally given at EA Global 2019) explains some of the mechanism design questions we need to answer to delegate open-ended questions to ML systems. It also discusses how experiments with human participants are making progress on these questions.
Previous posts: